I mentioned the term "Wall of Erasure" in my previous post about Iterator adapters. My friend Weiqi Gao described it best in his blog entry where he said 'Every really cool idea involving Java generics will invariably lead to insurmountable difficulties the root cause of which is erasure'.
I just got a chance to read Eric Burke's latest blog entries, and he too has hit the Wall of Erasure (some commentors are suggesting it's not "all" erasure's fault, but that's a red herring).
Monday, November 12, 2007
Monday, November 05, 2007
Unit Testing Simple Code
I just read Alex Miller's blog entry where he states quite nicely why unit testing even very simple code is not dumb. He posted because of Eric Burke's excellent discussion of the matter.
I really don't have much more to add, except to add one more voice to those who state that unit testing seemingly trivial code is important. I will say that I've actually caught silly mistakes (like failing to set a field to the correct value in a constructor) with simple unit tests. Also, writing tests for such code lets me spend more time thinking about the hard parts of the problem and less time examining 'simple' code to make sure it is correct.
I really don't have much more to add, except to add one more voice to those who state that unit testing seemingly trivial code is important. I will say that I've actually caught silly mistakes (like failing to set a field to the correct value in a constructor) with simple unit tests. Also, writing tests for such code lets me spend more time thinking about the hard parts of the problem and less time examining 'simple' code to make sure it is correct.
Sunday, November 04, 2007
Java 5+ Iterator Adapters
I've been working with Java Generics more lately, and have run smack into the "Wall of Erasure". I'm referring to the fact that generics disappear in the bytecode. As you probably know, generics were a targeted feature at a time when Sun was attempting to avoid changing the Java Virtual Machine (JVM). They really wanted to maintain backward compatibility. So, this compromise was put forth to maintain backward compatibility. In a classic case of irony, other changes forced a change the JVM in the same release that gave us generices, but the compromised version of generics stayed. So we are stuck with half an implementation of generics.
Recently, I've been doing work with interfaces and extending interfaces, as in:
I have classes which implement a third interface:
You would think that an implementation of DoesStuff could return an Iterator
Unfortunately, the Wall of Erasure means we can't do this. Try it for yourself if you don't believe me.
The sad thing is that this shouldn't be necessary. It's trivial. It shouldn't have to be written by developers. The simplicity of this is a clear sign that we need to tear down the Wall of Erasure.
Will it happen any time soon? I hope so. Though I'm hearing talk that "erasing erasure" is probably off the table for Java 7. That would be a truly sad thing.
Recently, I've been doing work with interfaces and extending interfaces, as in:
public interface Superclass {
// ...
}
public interface Subclass extends Superclass {
// ...
}
I have classes which implement a third interface:
public interface DoesStuff {
Iterator<Superclass > iterator();
// ...
}
You would think that an implementation of DoesStuff could return an Iterator
public class MyClass implements DoesStuff {
// ...
private Set<Subclass > myThings = new HashSet<Subclass >();
// ...
public Iterator<Superclass > iterator() {
return myThings.iterator();
}
// ...
}
Unfortunately, the Wall of Erasure means we can't do this. Try it for yourself if you don't believe me.
So, what to do? Happily, there is a simple answer. We create an adapter that adapts the subclass iterator to the superclass iterator:
/**
* Adapts a derived class iterator to a base class.
*/
public class IteratorAdapter<B, D extends B > implements Iterator<B > {
private Iterator<D> d;
public IteratorAdapter(Iterator<D > aD) {
d = aD;
}
public boolean hasNext() {
return d.hasNext();
}
public B next() {
return d.next();
}
public void remove() {
d.remove();
}
}
The sad thing is that this shouldn't be necessary. It's trivial. It shouldn't have to be written by developers. The simplicity of this is a clear sign that we need to tear down the Wall of Erasure.
Will it happen any time soon? I hope so. Though I'm hearing talk that "erasing erasure" is probably off the table for Java 7. That would be a truly sad thing.
Friday, October 26, 2007
Making BufferedReader Iterable
I was reading recently about a issues around reading an entire file into a string. I pretty much never do that, since I like my code to be robust even in the face of very large files. But it did get me thinking about reading in lines of a file one at a time. I do have reason to do that on occasion.
Originally, I might have done it something like this:
That's not bad, but I've been working with Ruby lately and really like the terse yet easy-to-read nature of the code. We can improve the above code with a for loop:
Better, but still not great. Now, what if the BufferedReader were Iterable? It isn't, but we can wrap an Iterable around it. First, let's look at usage:
Very nice. So, all we need is to implement BufferedReaderIterable. Happily, it's quite simple:
It would be nice if we could make the construction cleaner. What if BufferedReaderIterable had a constructor that took a File?
Now, usage is even cleaner:
[Editorial Note: Updated to put the template angle brackets back in after Eric Burke noticed Blogger was eating them]
Originally, I might have done it something like this:
File file = ...
BufferedReader br = new BufferedReader(new FileReader(file));
String line = br.readLine();
while ( line != null ) {
// Do something with line
line = br.readLine();
}
That's not bad, but I've been working with Ruby lately and really like the terse yet easy-to-read nature of the code. We can improve the above code with a for loop:
File file = ...
BufferedReader br = new BufferedReader(new FileReader(file));
for (String line = br.readLine(); line != null; line = br.readLine()) {
// Do something with line
}
Better, but still not great. Now, what if the BufferedReader were Iterable? It isn't, but we can wrap an Iterable around it. First, let's look at usage:
File file = ...
BufferedReaderIterable bri = new BufferedReaderIterable(new BufferedReader(new FileReader(file)));
for (String read : bri) {
// Do something with the line
}
Very nice. So, all we need is to implement BufferedReaderIterable. Happily, it's quite simple:
public class BufferedReaderIterable implements Iterable<String > {
private Iterator<String > i;
public BufferedReaderIterable( BufferedReader br ) {
i = new BufferedReaderIterator( br );
}
public Iteratoriterator() {
return i;
}
private class BufferedReaderIterator implements Iterator<String > {
private BufferedReader br;
private java.lang.String line;
public BufferedReaderIterator( BufferedReader aBR ) {
(br = aBR).getClass();
advance();
}
public boolean hasNext() {
return line != null;
}
public String next() {
String retval = line;
advance();
return retval;
}
public void remove() {
throw new UnsupportedOperationException("Remove not supported on BufferedReader iteration.");
}
private void advance() {
try {
line = br.readLine();
}
catch (IOException e) { /* TODO */}
}
}
}
It would be nice if we could make the construction cleaner. What if BufferedReaderIterable had a constructor that took a File?
public class BufferedReaderIterable implements Iterable<String > {
private BufferedReader mine;
private Iterator<String > i;
public BufferedReaderIterable( BufferedReader br ) {
i = new BufferedReaderIterator( br );
}
public BufferedReaderIterable( File f ) throws FileNotFoundException {
mine = new BufferedReader( new FileReader( f ) );
i = new BufferedReaderIterator( mine );
}
public Iterator<String > iterator() {
return i;
}
private class BufferedReaderIterator implements Iterator<String > {
private BufferedReader br;
private String line;
public BufferedReaderIterator( BufferedReader aBR ) {
(br = aBR).getClass();
advance();
}
public boolean hasNext() {
return line != null;
}
public String next() {
String retval = line;
advance();
return retval;
}
public void remove() {
throw new UnsupportedOperationException("Remove not supported on BufferedReader iteration.");
}
private void advance() {
try {
line = br.readLine();
}
catch (IOException e) { /* TODO */}
if ( line == null && mine != null ) {
try {
mine.close();
}
catch (IOException e) { /* Ignore - probably should log an error */ }
mine = null;
}
}
}
}
Now, usage is even cleaner:
File file = ...
BufferedReaderIterable bri = new BufferedReaderIterable(file);
for (String read : bri) {
// Do something with the line
}
[Editorial Note: Updated to put the template angle brackets back in after Eric Burke noticed Blogger was eating them]
Tuesday, September 18, 2007
Eric Burke suppressing a desire to get a Mac?
My friend and colleague, Eric Burke, recently altered his blog to show the date of the posting with a calendar 'icon' rendered by a CSS style-sheet. While I appreciate his frustration with the inconsistent handling of CSS by different browsers, that is not what caught my eye. Here is his graphic:

And here is the icon for iCal (the calendar program on Mac OS X):

What do you think? Is he is suppressing a desire to get a Mac?

And here is the icon for iCal (the calendar program on Mac OS X):

What do you think? Is he is suppressing a desire to get a Mac?
Wednesday, August 08, 2007
Gilstrap Estimation Curves
I am constantly producing estimates. How long will this project take? How long will that feature take? How long will it take us to test things? And my favorite: How long will it take to fix the bugs we haven't found?
Other than the last, nonsense question, these are legitimate issues to address in the process of software development. Unfortunately, our industry (and some others) tends to be very simplistic in their estimates.
There are many ways to go wrong in estimating. Perhaps the the most common is attempting to pretend that people are 'resources' and that everyone is interchangeable. But that's a topic for another day. Today, I want to look at a way of estimating that is simple enough to use yet isn't one dimensional.
One of the biggest problems with estimating is trying to incorporate some notion of risk in the estimate. Is your estimate iron-clad, where you are 99.99999% sure you'll meet the deadline (and consequently there's a chance you can beat it), or will you be working flat-out trying to meet the date with only a limited chance of making it? This is one of the most common problems in projects: one party gives an aggressive estimate and another party assumes it's conservative. We need a better way to communicate the likelihood of completing a task in a given amount of time.
To capture this idea, we need to represent the work with more than a single number, and we need to incorporate risk. Happily, this lends itself to a two-dimensional graph, with effort (time) as the x-axis and likelihood of completion (what I'll call "confidence") as the y-axis, like this:

The line represents your confidence, at the time you make the estimate, that you will solve the problem with the effort specified. Depending on the scope of the work, the effort line might be measured in hours, days, weeks, months, or even years. The basic idea is that it will take some period of time to understand the unknowns of a problem, which is the early, low-confidence part of the curve. Once the basic problem is understood work proceeds apace, and confidence goes up rapidly. The tail of the curve represents the fact that things might go well and we could get done earlier than expected. Let's take an example.
Assume you are asked to implement a new kind of cache for your system. It involves a "least recently used" (LRU) strategy along with a maximum age for cache entries. Instead of saying "it'll take 10 man-days of effort", as if it can not take only 9 or would never take 11, you can graph it, like this:

This says that you think there's about a 2% chance of completing the work in 1 man-day, a 20% chance in four man-days, a 90% chance you'll get done in 8 days, etc. You are not saying you'll be done in a specific number of man-days. Instead, you provide an estimate of the likelihood you'll complete the work in a particular number of man-days. This is useful because it helps provide some insight into the overall risk you see in the work.
This is not to say that all problems follow this curve. Some may in fact be so difficult that they never approach 100%. For example, if you thought there was only a 50% chance you would actually be able to come up with a solution to a problem, you might have a graph like this:

Similarly, if you think the problem is well-understood, your graph might look like this:

At first this might seem odd. But if you really understand the problem you'll be able to estimate the required effort very accurately. This means there's very little chance of getting done faster than your estimate, but it also means there's very little chance you'll run long.
Perhaps this is a well-known thing in project management circles, but I've never seen anything like it in over twenty years in industry. I plan to use these estimation curves to better communicate my estimates to others.
Other than the last, nonsense question, these are legitimate issues to address in the process of software development. Unfortunately, our industry (and some others) tends to be very simplistic in their estimates.
There are many ways to go wrong in estimating. Perhaps the the most common is attempting to pretend that people are 'resources' and that everyone is interchangeable. But that's a topic for another day. Today, I want to look at a way of estimating that is simple enough to use yet isn't one dimensional.
One of the biggest problems with estimating is trying to incorporate some notion of risk in the estimate. Is your estimate iron-clad, where you are 99.99999% sure you'll meet the deadline (and consequently there's a chance you can beat it), or will you be working flat-out trying to meet the date with only a limited chance of making it? This is one of the most common problems in projects: one party gives an aggressive estimate and another party assumes it's conservative. We need a better way to communicate the likelihood of completing a task in a given amount of time.
To capture this idea, we need to represent the work with more than a single number, and we need to incorporate risk. Happily, this lends itself to a two-dimensional graph, with effort (time) as the x-axis and likelihood of completion (what I'll call "confidence") as the y-axis, like this:

The line represents your confidence, at the time you make the estimate, that you will solve the problem with the effort specified. Depending on the scope of the work, the effort line might be measured in hours, days, weeks, months, or even years. The basic idea is that it will take some period of time to understand the unknowns of a problem, which is the early, low-confidence part of the curve. Once the basic problem is understood work proceeds apace, and confidence goes up rapidly. The tail of the curve represents the fact that things might go well and we could get done earlier than expected. Let's take an example.
Assume you are asked to implement a new kind of cache for your system. It involves a "least recently used" (LRU) strategy along with a maximum age for cache entries. Instead of saying "it'll take 10 man-days of effort", as if it can not take only 9 or would never take 11, you can graph it, like this:

This says that you think there's about a 2% chance of completing the work in 1 man-day, a 20% chance in four man-days, a 90% chance you'll get done in 8 days, etc. You are not saying you'll be done in a specific number of man-days. Instead, you provide an estimate of the likelihood you'll complete the work in a particular number of man-days. This is useful because it helps provide some insight into the overall risk you see in the work.
This is not to say that all problems follow this curve. Some may in fact be so difficult that they never approach 100%. For example, if you thought there was only a 50% chance you would actually be able to come up with a solution to a problem, you might have a graph like this:

Similarly, if you think the problem is well-understood, your graph might look like this:

At first this might seem odd. But if you really understand the problem you'll be able to estimate the required effort very accurately. This means there's very little chance of getting done faster than your estimate, but it also means there's very little chance you'll run long.
Perhaps this is a well-known thing in project management circles, but I've never seen anything like it in over twenty years in industry. I plan to use these estimation curves to better communicate my estimates to others.
Tuesday, July 31, 2007
RemoteIterator, episode 2
Last time, I lamented the lack of a standard RemoteIterator interface in Java. I went on to show a version that showed up not long ago in Jackrabbit (an implementation of JSR 170) and the version I've recreated several times in the past. Let's take a quick look at them again.
Jackrabbit's:
The RemoteIterator interface I've recreated a number of times over the years:
Let's go through the methods individually:
So, where does this leave us? Our RemoteIterator now looks like this:
I'm still wondering why this isn't part of the JDK.
Jackrabbit's:
public interface RemoteIterator extends Remote {
long getSize() throws RemoteException;
void skip(long items) throws NoSuchElementException, RemoteException;
Object[] nextObjects() throws IllegalArgumentException, RemoteException;
}
The RemoteIterator interface I've recreated a number of times over the years:
public interface RemoteIterator<T > extends Remote {
public boolean hasMore() throws RemoteException;
public List<T > next( int preferredBatchSize ) throws RemoteException;
}
Let's go through the methods individually:
- long getSize() throws RemoteException
This seems problematic to me. Perhaps in Jackrabbit, it is reasonable to assume that you will always know the size of the collection to be iterated. But in many situations, this is not the case. For example, if the iterator is ultimately coming from a database cursor and the collection is large, we want to avoid having to run two SQL queries or store the entire collection in memory (which may be prohibitively expensive). I can see a derived interface, perhaps named BoundedRemoteIterator or something, but not in this interface. - void skip(long items) throws NoSuchElementException, RemoteException
I love this idea. Wish I'd thought of it myself. A trivial implementation would do whatever next( items ), would do and simply not return the items. A smart implementation can save time and space by not actually generating the objects (since they won't be returned). The only change I would make is to have a return value of the number of items skipped and get rid of the NoSuchElementException. If I ask to skip 50 items and only 29 more exist, I would get a return of 29 and no exception. Admittedly, if the interface included a getSize operation, throwing NoSuchElementException is less strange. But even in that case, it seems too rigid to consider skipping more items than are left an 'exception'. - boolean hasMore() throws RemoteException
At first, you might think this is a wasteful operation. Why make a call to find out if there are more items? This results in 'extra' remote calls instead of simply asking for the next item. However, if we imagine the items themselves as quite large (e.g. multi-megapixel images), we start to see a use for this API. If we were keeping the getSize operation, this might not be necessary, but again, getSize() requires state tracking on the client side that can substantially complicate the client code. - Object[] nextObjects() throws IllegalArgumentException, RemoteException
This is similar to my next operation discussed below, except (1) it throws IllegalArgumentException, (2) returns an array of objects instead of a List of a specific type, and (3) does not take a preferred size.
(1) I'm guessing that the getSize operation is intended to be called and then the caller is expected to know when all items in the iterator are consumed. This creates a problem if the client consumes different parts of the iterator in different parts of the code. Now, they have to pass around 2 or 3 items (remote iterator, number of items consumed so far, and possibly the total size) to do this. This is clunky to say the least.
(2) Jackrabbit may have been specified before 1.5 was in wide use, or may feel the need for backward compatibility, hence the use of an array of Object. The downside to this is the loss of type-safety and loss of an API that can be optimized. See the discussion of next below.
(3) See the discussion of next below for the rationale for a preferred batch size. - List<T> next( int preferredBatchSize ) throws RemoteException
By returning a List<T>, we not only introduce type information/safety, we also allow for further optimization. The List returned could be a simple implementation such as LinkedList or ArrayList. Or, it could be a smart List that collaborates with the RemoteIterator to delay retrieving its contents or retrieve the contents in separate threads. There are lots of possibilities introduced by avoiding raw Java arrays.
Allowing the client to pass a preferred batch size provides many optimization opportunities. For example, if displaying the items in a GUI, they can ask for 'page-sized' numbers of items. By making the preferred size a suggestion, it allows an implementation leeway to ignore requests that are deemed unmanageably small or large for the kind of information being returned.
So, where does this leave us? Our RemoteIterator now looks like this:
import java.rmi.Remote;
import java.rmi.RemoteException;
import java.util.List;
/**
* Interface for a remote iterator that returns entries of a particular type.
* @see java.util.Iterator
* @see java.rmi.Remote
*/
public interface RemoteIterator<T > extends Remote {
/**
* Determine if there are more items to be iterated across
* @return true if there are more items to be
* iterated, false otherwise.
* @throws RemoteException if a problem occurs with
* communication or on the remote server.
*/
boolean hasMore() throws RemoteException;
/**
* Skip some number of items.
* @param items the number of items to skip at maximum. If there are fewer
* items than this left, all remaining items are skipped.
* @return the number of itmes actually skipped. This will equal <code >items</code >
* unless there were not that many items left in the iteration.
* @throws RemoteException if a problem occurs with
* communication or on the remote server.
*/
int skip(long items) throws RemoteException;
/**
* Get some number of items
* @param preferredBatchSize a suggested number of items to return. The implementation
* is not required to honor this request if it will prove too difficult.
* @return a List of the next items in the iteration, in iteration order.
* @throws RemoteException if a problem occurs with
* communication or on the remote server.
*/
List<T > next( int preferredBatchSize ) throws RemoteException;
}
I'm still wondering why this isn't part of the JDK.
Thursday, July 19, 2007
RemoteIterator, where art thou?
I've written my fair share of remote iterators over the years. The concept is simple enough: provide an interface for iterating over a set of items that come from a remote source. The harder part is making a good abstraction that can still perform well.
Even so, it surprises me that, as far as I can tell, there hasn't been a standardized form of this. There's been discussion for a long time, with my earliest memories stemming from the JINI mailing lists back in 2001. Yet there's nothing in the core as of Java 6. There are random postings on various groups on the subject through the years, but no actual API that I can find.
Recently, I was teaching my course in Java performance tuning and discussing remote iterators, when a student mentioned that Jackrabbit (an implementation of JSR 170) has an RMI remoting API called Jackrabbit JCR-RMI which includes a RemoteIterator. As of version 1.0.1, it looks like this:
Here is the RemoteIterator interface I've recreated a number of times over the years:
These two APIs are strikingly similar. They both extend Remote, they both provide a means to get some number of the next items to be retrieved (mine with generics and theirs without), and they are both quite small. Yet they are also strikingly different: JackRabbit's API has both getSize and skip while mine doesn't.
Next time, I'll describe what I see as the major differences and what I like about each. I'll also compare the client-side front-end for remote iterators from Jackrabbit and the one I've created. In the mean time, consider it a challenge to comment about everything I was going to bring up and more.
Even so, it surprises me that, as far as I can tell, there hasn't been a standardized form of this. There's been discussion for a long time, with my earliest memories stemming from the JINI mailing lists back in 2001. Yet there's nothing in the core as of Java 6. There are random postings on various groups on the subject through the years, but no actual API that I can find.
Recently, I was teaching my course in Java performance tuning and discussing remote iterators, when a student mentioned that Jackrabbit (an implementation of JSR 170) has an RMI remoting API called Jackrabbit JCR-RMI which includes a RemoteIterator. As of version 1.0.1, it looks like this:
public interface RemoteIterator extends Remote {
long getSize() throws RemoteException;
void skip(long items) throws NoSuchElementException, RemoteException;
Object[] nextObjects() throws IllegalArgumentException, RemoteException;
}
Here is the RemoteIterator interface I've recreated a number of times over the years:
public interface RemoteIteratorextends Remote {
public boolean hasMore() throws RemoteException;
public Listnext( int preferredBatchSize ) throws RemoteException;
}
These two APIs are strikingly similar. They both extend Remote, they both provide a means to get some number of the next items to be retrieved (mine with generics and theirs without), and they are both quite small. Yet they are also strikingly different: JackRabbit's API has both getSize and skip while mine doesn't.
Next time, I'll describe what I see as the major differences and what I like about each. I'll also compare the client-side front-end for remote iterators from Jackrabbit and the one I've created. In the mean time, consider it a challenge to comment about everything I was going to bring up and more.
Monday, July 02, 2007
Random Acts of Blog
I've been subscribed to Brian Coyner's blog for some time. I had this URL:
feed://beanman.wordpress.com/atom.xml
Recently, I was quite surprised when Brian seemed to stop blogging about software and began blogging about bands I had no idea he liked. But I chalked it up to a sudden burst of music interest.
Then, today, I tried to go to his blog and got this:

It turns out to be a blog feed for People Magazine's StyleWatch. WTF? A bit of digging and it would seem that the feed above no longer works. But instead of giving me an error, I'm directed to a random wordpress.com blog page instead. Talk about non-intuitive!
Freaky....
feed://beanman.wordpress.com/atom.xml
Recently, I was quite surprised when Brian seemed to stop blogging about software and began blogging about bands I had no idea he liked. But I chalked it up to a sudden burst of music interest.
Then, today, I tried to go to his blog and got this:

It turns out to be a blog feed for People Magazine's StyleWatch. WTF? A bit of digging and it would seem that the feed above no longer works. But instead of giving me an error, I'm directed to a random wordpress.com blog page instead. Talk about non-intuitive!
Freaky....
Thursday, June 28, 2007
Friday Java Quiz
My friend, Weiqi Gao, frequently posts a Friday Java Quiz . I ran into a situation today that seems like a good one.
Suppose you have the following two classes:
Without running this program, do you know what the output will be?
Suppose you have the following two classes:
public class Test {
public static void main(String[] args) {
System.err.println( Foo.class.getName() );
System.err.println( "Testing, 1, 2, 3..." );
new Foo();
}
}
public class Foo {
static {
System.err.println( "Foo here." );
}
public Foo() {
System.err.println( "New Foo!" );
}
}
Without running this program, do you know what the output will be?
Thursday, May 17, 2007
Kyle Cordes on tools
Kyle Cordes wants people to view a presentation by Linus Torvalds discussing distributed version control tools. I plan to watch the talk soon, but a comment Kyle made in his blog entry really rang true. It's something I've been saying (less eloquently) for a long time:
"I have heard it said that these are all 'just tools' which don’t matter, you simply use whatever the local management felt like buying. That is wrong: making better tool choices will make your project better (cheaper, faster, more fun, etc.), making worse tool choices will make your project worse (more expensive, slower, painful, higher turnover, etc.)"
"I have heard it said that these are all 'just tools' which don’t matter, you simply use whatever the local management felt like buying. That is wrong: making better tool choices will make your project better (cheaper, faster, more fun, etc.), making worse tool choices will make your project worse (more expensive, slower, painful, higher turnover, etc.)"
Friday, April 06, 2007
I've been tagged
There is apparently a blog-tag game going around, and Jeff Brown tagged me.
Now I'm tagging Weiqi, Brad, Dave, Brian, and Melben.
- I practice Yang-style short form T'ai Chi Ch'uan.
- I've been having fun lately making home-made no knead bread.
- I enjoy woodworking. I'm currently tuning my latest large tool purchase. It took me about a year to save enough to get my bandsaw. I even build things.
- I've used a Mac since the original 128k version introduced in 1984.
- Perhaps because I didn't drink much as a teenager, I never developed a taste for beer. I do enjoy single malt scotch.
{kind=link}
Now I'm tagging Weiqi, Brad, Dave, Brian, and Melben.
Tuesday, March 20, 2007
Too much C++
(with apologies to Monty Python)
A customer enters a software shop.
Mr. Praline: 'Ello, I wish to register a complaint.
The owner does not respond.
Mr. Praline: 'Ello, Miss?
Owner: What do you mean "miss"?
Mr. Praline: I'm sorry, I have a cold. I wish to make a complaint!
Owner: We're closin' for lunch.
Mr. Praline: Never mind that, my lad. I wish to complain about this programming language what I purchased not half an hour ago from this very boutique.
Owner: Oh yes, the, uh, the Danish C++...What's,uh...What's wrong with it?
Mr. Praline: I'll tell you what's wrong with it, my lad. 'E's crap, that's what's wrong with it!
Owner: No, no, 'e's uh,...it's resting.
Mr. Praline: Look, matey, I know a crap language when I see one, and I'm looking at one right now.
Owner: No no it's not crap, it's, it's restin'! Remarkable language, the Danish C++, idn'it, ay? Beautiful syntax!
Mr. Praline: The syntax don't enter into it. It's stone crap.
Owner: Nononono, no, no! 'E's resting!
Mr. Praline: All right then, if it's restin', I'll wake him up! (shouting at the cage) 'Ello, Mister Plymorphic Language! I've got a lovely fresh computer for you if you show...
owner hits the cage
Owner: There, he moved!
Mr. Praline: No, he didn't, that was you hitting the cage!
Owner: I never!!
Mr. Praline: Yes, you did!
Owner: I never, never did anything...
Mr. Praline: (yelling and hitting the cage repeatedly) 'ELLO POLYMORPH!!!!! Testing! Testing! Testing! Testing! This is your nine o'clock alarm call!
Takes language out of the cage and thumps its head on the counter. Throws it up in the air and watches it plummet to the floor.
Mr. Praline: Now that's what I call a crap language.
Owner: No, no.....No, 'e's stunned!
Mr. Praline: STUNNED?!?
Owner: Yeah! You stunned him, just as he was wakin' up! Danish C++'s stun easily, major.
Mr. Praline: Um...now look...now look, mate, I've definitely 'ad enough of this. That language is definitely deceased, and when I purchased it not 'alf an hour ago, you assured me that its total lack of movement was due to it bein' tired and shagged out following a prolonged standards meeting.
Owner: Well, it's...it's, ah...probably pining for a common runtime.
Mr. Praline: PININ' for a COMMON RUNTIME?!?!?!? What kind of talk is that?, look, why did he fall flat on his back the moment I got 'im home?
Owner: The Danish C++ prefers keepin' on it's back! Remarkable language, id'nit, squire? Lovely syntax!
Mr. Praline: Look, I took the liberty of examining that language when I got it home, and I discovered the only reason that it had been sitting on its perch in the first place was that it had been NAILED there.
pause
Owner: Well, o'course it was nailed there! If I hadn't nailed that language down, it would have nuzzled up to those computers, broke 'em apart with its beak, and VOOM! Feeweeweewee!
Mr. Praline: "VOOM"?!? Mate, this language wouldn't "voom" if you put four million volts through it! 'E's bleedin' demised!
Owner: No no! 'E's pining!
Mr. Praline: 'E's not pinin'! 'E's passed on! This language is no more! He has ceased to be! 'E's expired and gone to meet 'is maker! 'E's a stiff! Bereft of life, 'e rests in peace! If you hadn't nailed 'im to the perch 'e'd be pushing up the daisies! 'Is processes are now 'istory! 'E's off the map! 'E's kicked the bucket, 'e's shuffled off 'is mortal coil, run down the curtain and joined the bleedin' choir invisibile!! THIS IS AN EX-LANGUAGE!!
pause
Owner: Well, I'd better replace it, then. (he takes a quick peek behind the counter) Sorry squire, I've had a look 'round the back of the shop, and uh, we're right out of languages.
Mr. Praline: I see. I see, I get the picture.
Owner: I got Java.
pause
Mr. Praline: Pray, does it support pointers?
Owner: Nnnnot really.
Mr. Praline: WELL IT'S HARDLY A BLOODY REPLACEMENT, IS IT?!!???!!?
Owner: N-no, I guess not. (gets ashamed, looks at his feet)
Mr. Praline: Well.
pause
Owner: (quietly) D'you.... d'you want to come back to my place an' dereference some pointers?
Mr. Praline: (looks around) Yeah, all right, sure.
A customer enters a software shop.
Mr. Praline: 'Ello, I wish to register a complaint.
The owner does not respond.
Mr. Praline: 'Ello, Miss?
Owner: What do you mean "miss"?
Mr. Praline: I'm sorry, I have a cold. I wish to make a complaint!
Owner: We're closin' for lunch.
Mr. Praline: Never mind that, my lad. I wish to complain about this programming language what I purchased not half an hour ago from this very boutique.
Owner: Oh yes, the, uh, the Danish C++...What's,uh...What's wrong with it?
Mr. Praline: I'll tell you what's wrong with it, my lad. 'E's crap, that's what's wrong with it!
Owner: No, no, 'e's uh,...it's resting.
Mr. Praline: Look, matey, I know a crap language when I see one, and I'm looking at one right now.
Owner: No no it's not crap, it's, it's restin'! Remarkable language, the Danish C++, idn'it, ay? Beautiful syntax!
Mr. Praline: The syntax don't enter into it. It's stone crap.
Owner: Nononono, no, no! 'E's resting!
Mr. Praline: All right then, if it's restin', I'll wake him up! (shouting at the cage) 'Ello, Mister Plymorphic Language! I've got a lovely fresh computer for you if you show...
owner hits the cage
Owner: There, he moved!
Mr. Praline: No, he didn't, that was you hitting the cage!
Owner: I never!!
Mr. Praline: Yes, you did!
Owner: I never, never did anything...
Mr. Praline: (yelling and hitting the cage repeatedly) 'ELLO POLYMORPH!!!!! Testing! Testing! Testing! Testing! This is your nine o'clock alarm call!
Takes language out of the cage and thumps its head on the counter. Throws it up in the air and watches it plummet to the floor.
Mr. Praline: Now that's what I call a crap language.
Owner: No, no.....No, 'e's stunned!
Mr. Praline: STUNNED?!?
Owner: Yeah! You stunned him, just as he was wakin' up! Danish C++'s stun easily, major.
Mr. Praline: Um...now look...now look, mate, I've definitely 'ad enough of this. That language is definitely deceased, and when I purchased it not 'alf an hour ago, you assured me that its total lack of movement was due to it bein' tired and shagged out following a prolonged standards meeting.
Owner: Well, it's...it's, ah...probably pining for a common runtime.
Mr. Praline: PININ' for a COMMON RUNTIME?!?!?!? What kind of talk is that?, look, why did he fall flat on his back the moment I got 'im home?
Owner: The Danish C++ prefers keepin' on it's back! Remarkable language, id'nit, squire? Lovely syntax!
Mr. Praline: Look, I took the liberty of examining that language when I got it home, and I discovered the only reason that it had been sitting on its perch in the first place was that it had been NAILED there.
pause
Owner: Well, o'course it was nailed there! If I hadn't nailed that language down, it would have nuzzled up to those computers, broke 'em apart with its beak, and VOOM! Feeweeweewee!
Mr. Praline: "VOOM"?!? Mate, this language wouldn't "voom" if you put four million volts through it! 'E's bleedin' demised!
Owner: No no! 'E's pining!
Mr. Praline: 'E's not pinin'! 'E's passed on! This language is no more! He has ceased to be! 'E's expired and gone to meet 'is maker! 'E's a stiff! Bereft of life, 'e rests in peace! If you hadn't nailed 'im to the perch 'e'd be pushing up the daisies! 'Is processes are now 'istory! 'E's off the map! 'E's kicked the bucket, 'e's shuffled off 'is mortal coil, run down the curtain and joined the bleedin' choir invisibile!! THIS IS AN EX-LANGUAGE!!
pause
Owner: Well, I'd better replace it, then. (he takes a quick peek behind the counter) Sorry squire, I've had a look 'round the back of the shop, and uh, we're right out of languages.
Mr. Praline: I see. I see, I get the picture.
Owner: I got Java.
pause
Mr. Praline: Pray, does it support pointers?
Owner: Nnnnot really.
Mr. Praline: WELL IT'S HARDLY A BLOODY REPLACEMENT, IS IT?!!???!!?
Owner: N-no, I guess not. (gets ashamed, looks at his feet)
Mr. Praline: Well.
pause
Owner: (quietly) D'you.... d'you want to come back to my place an' dereference some pointers?
Mr. Praline: (looks around) Yeah, all right, sure.
Thursday, March 15, 2007
The ever-leaky abstractions of Microsoft
I was using Windows XP inside Parallels today and got a message from Windows that I had never seen before:

How on earth could you design an operating system that could detect there wasn't enough virtual memory, expand the virtual memory pool automatically, but would deny applications requests for virtual memory at the same time?

How on earth could you design an operating system that could detect there wasn't enough virtual memory, expand the virtual memory pool automatically, but would deny applications requests for virtual memory at the same time?
Thursday, March 01, 2007
C++ Unit testing frameworks: do they all suck?
Well, I've been doing some work with C++ lately and I quickly ran into the need for a unit testing framework. I found an excellent article reviewing the state of C++ unit testing frameworks. My first surprise was how many of them there are. This article alone reviewed six of them. Even if those are all of the 'serious contenders', that's about 3 or 4 frameworks too many.
I was also surprised at how primitive the C++ unit testing frameworks feel. I realized after a while that the lack of dynamic/reflective behavior in C++ is part (or even all) of the issue. Since reflection is not built in, many of the grungy tasks that unit testing frameworks in Java automate for us can't be automated in a C++ unit testing framework. What a shame. We're left using frameworks that feel awkard and leave a lot to be desired.
Then I got to thinking: a number of the C++ wizards around here talk about the power of C++ template programming. It seems to me it ought to be possible to clean up and automate what would normally be done in Java with reflection using templates in C++. I wonder why this hasn't been done. I don't know templates well enough to do it myself, but I hope some wiz at C++ templates does this sometime soon.
For now, I'll keep trudging along with CppUnit, and maybe try out CxxTest.
I was also surprised at how primitive the C++ unit testing frameworks feel. I realized after a while that the lack of dynamic/reflective behavior in C++ is part (or even all) of the issue. Since reflection is not built in, many of the grungy tasks that unit testing frameworks in Java automate for us can't be automated in a C++ unit testing framework. What a shame. We're left using frameworks that feel awkard and leave a lot to be desired.
Then I got to thinking: a number of the C++ wizards around here talk about the power of C++ template programming. It seems to me it ought to be possible to clean up and automate what would normally be done in Java with reflection using templates in C++. I wonder why this hasn't been done. I don't know templates well enough to do it myself, but I hope some wiz at C++ templates does this sometime soon.
For now, I'll keep trudging along with CppUnit, and maybe try out CxxTest.
Thursday, February 01, 2007
Adding a JNI Library template to Xcode
I've been doing some work with Xcode, Apple's IDE, recently. I wanted to use it for doing Java JNI work, since I'm doing some of that, but found the normal tutorial assumes you are building an entire application with Xcode. Well, Xcode pales in comparison to IDEA for working with Java.
So I wondered if I could use IDEA for working with the Java code and Xcode for managing the JNI bindings and the C++ code that goes with it. After a bit of playing around (primarily pulling bits and pieces from Apple's mini-tutorial on JNI with Xcode), I figured out how to build a JNI library that I can use easily from IDEA.
That got me to thinking about the four or five steps I would have to do each time I created a new one of these projects (which I expect to be doing for a while). I vaguely remembered a friend talking about customizing Xcode by creating new templates. So I set out to create one for building JNI libraries.
I googled around a bit and found out that Xcode keeps its templates in:
Looking there, I see a folder called "Project Templates", and sure enough inside are all the templates for Xcode projects.
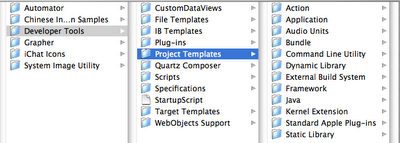
There are several that look promising, but what's the difference between a "BSD Dynamic Library", a "C++ Dynamic Library", and a "C++ Standard Dynamic Library"? Something based on the "C++ Standard Dynamic Library" seems right.
So, I create a test project and make a few changes to produce a JNI library:
Now, save the project, make sure it builds (which it does) and create a simple Java HelloWorld with a native method that calls our Test class.
Having verified that this sort of project can be used to produce a JNI Library, it's time to create the custom project template. First I copy the "C++ Standard Dynamic Library template" to "JNI C++ Standard Dynamic Library". Now I need to find the right places to insert the additional items that were changed (and how to remove the Carbon framework). Looking at the template directory, I see a number of files.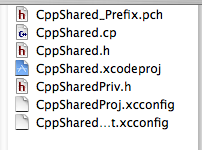 But most of these are just boilerplate for source files in the project ('.pch', '.h', '.cp'). I think I can safely ignore these files at least for now (though I made note of them; if there prove to be certain common files in my JNI libraries moving forward, I can come back and try to tweak the project template to have different boilerplates).
But most of these are just boilerplate for source files in the project ('.pch', '.h', '.cp'). I think I can safely ignore these files at least for now (though I made note of them; if there prove to be certain common files in my JNI libraries moving forward, I can come back and try to tweak the project template to have different boilerplates).
The key 'file' appears to be CppShared.xcodeproj. Right-clicking on it shows it is really a 'package' and I take a look inside.
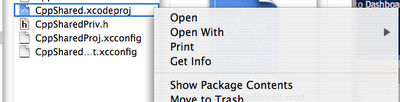
When I do so, I see two files: "TemplateInfo.plist" and "project.pbxproj". The '.plist' file has some interesting items about template files and lists of files upon which to perform macro expansion. Interestingly, the list of files matches the list of boilerplate files almost exactly. For now, I'm leaving these alone (again making note in case I want to change the set of boilerplate files in the project). There is also a Description item, which shows up in the "New Project..." window in Xcode. After tweaking that to make it better describe this new kind of project I'm creating, I move on to the "project.pbxproj" file.
The "project.pbxproj" file is semi-text and semi-binary. So it's time to be careful and make a backup before experimenting. The first section of interest is this:
I ditch the Carbon framework reference (since I'm doing JNI) by deleting the line that references Carbon. If I want to use Carbon in a JNI library, I can always add it later. It turns out there are a bunch of other references to Carbon in the template, and I have to remove those as well.
Now, I see the line that makes reference to "lib«PROJECTNAME».dylib". I want the library to end with '.jnilib' since that is required by Mac OS X. So I patch this:
Now, I want the header search paths to include the location of the Java headers, and the executable extension to be '.jnilib'. Searching the test project's '.pbxproj' file, I find them in the Debug and Release build sections. However, there are two pairs of these, one pair for the library target and one pair for the overall project. I need to change the ones for the overall project:
I was encouraged when creating a new project didn't fail. Looking at the default setup, everything seems to be in order (no Carbon framework, all the boilerplate files are there, etc.). A few minutes to add in the JNI binding function and change the Java program to use the new JNI library and I have a successful test.
I'm sure there are many other customizations I could make if I only knew about them. I also wish there were a better tool than a text editor for editing these files (hopefully there is and someone will point it out to me).
So I wondered if I could use IDEA for working with the Java code and Xcode for managing the JNI bindings and the C++ code that goes with it. After a bit of playing around (primarily pulling bits and pieces from Apple's mini-tutorial on JNI with Xcode), I figured out how to build a JNI library that I can use easily from IDEA.
That got me to thinking about the four or five steps I would have to do each time I created a new one of these projects (which I expect to be doing for a while). I vaguely remembered a friend talking about customizing Xcode by creating new templates. So I set out to create one for building JNI libraries.
I googled around a bit and found out that Xcode keeps its templates in:
/Library/Application Support/Apple/Developer Tools
Looking there, I see a folder called "Project Templates", and sure enough inside are all the templates for Xcode projects.

There are several that look promising, but what's the difference between a "BSD Dynamic Library", a "C++ Dynamic Library", and a "C++ Standard Dynamic Library"? Something based on the "C++ Standard Dynamic Library" seems right.
So, I create a test project and make a few changes to produce a JNI library:
- Change "Executable Extension" to be "jnilib"
- Change "Header Search Paths" to include "$(SDK)/System/Library/Frameworks/JavaVM.framework/Headers"
- Delete the Carbon framework (why was it there in the first place?)
Now, save the project, make sure it builds (which it does) and create a simple Java HelloWorld with a native method that calls our Test class.
Having verified that this sort of project can be used to produce a JNI Library, it's time to create the custom project template. First I copy the "C++ Standard Dynamic Library template" to "JNI C++ Standard Dynamic Library". Now I need to find the right places to insert the additional items that were changed (and how to remove the Carbon framework). Looking at the template directory, I see a number of files.
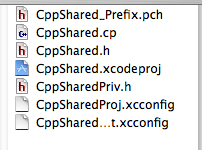 But most of these are just boilerplate for source files in the project ('.pch', '.h', '.cp'). I think I can safely ignore these files at least for now (though I made note of them; if there prove to be certain common files in my JNI libraries moving forward, I can come back and try to tweak the project template to have different boilerplates).
But most of these are just boilerplate for source files in the project ('.pch', '.h', '.cp'). I think I can safely ignore these files at least for now (though I made note of them; if there prove to be certain common files in my JNI libraries moving forward, I can come back and try to tweak the project template to have different boilerplates).The key 'file' appears to be CppShared.xcodeproj. Right-clicking on it shows it is really a 'package' and I take a look inside.

When I do so, I see two files: "TemplateInfo.plist" and "project.pbxproj". The '.plist' file has some interesting items about template files and lists of files upon which to perform macro expansion. Interestingly, the list of files matches the list of boilerplate files almost exactly. For now, I'm leaving these alone (again making note in case I want to change the set of boilerplate files in the project). There is also a Description item, which shows up in the "New Project..." window in Xcode. After tweaking that to make it better describe this new kind of project I'm creating, I move on to the "project.pbxproj" file.
The "project.pbxproj" file is semi-text and semi-binary. So it's time to be careful and make a backup before experimenting. The first section of interest is this:
/* Begin PBXFileReference section */
08FB77AAFE841565C02AAC07 /* Carbon.framework */ = {isa = ...
32BAE0B70371A74B00C91783 /* «PROJECTNAME»_Prefix.pch */ = {isa = ...
50149BD909E781A5002DEE6A /* «PROJECTNAME».h */ = {isa = ...
5073E0C409E734A800EC74B6 /* «PROJECTNAME».cp */ = {isa = ...
5073E0C609E734A800EC74B6 /* «PROJECTNAME»Proj.xcconfig */ = {isa = ...
5073E0C709E734A800EC74B6 /* «PROJECTNAME»Target.xcconfig */ = {isa = ...
50B2938909F016FC00694E55 /* «PROJECTNAME»Priv.h */ = {isa = ...
D2AAC09D05546B4700DB518D /* lib«PROJECTNAME».dylib */ = {isa =
PBXFileReference; explicitFileType = "compiled.mach-o.dylib";
includeInIndex = 0; path = "lib«PROJECTNAME».dylib"; sourceTree = BUILT_PRODUCTS_DIR; };
/* End PBXFileReference section */
I ditch the Carbon framework reference (since I'm doing JNI) by deleting the line that references Carbon. If I want to use Carbon in a JNI library, I can always add it later. It turns out there are a bunch of other references to Carbon in the template, and I have to remove those as well.
Now, I see the line that makes reference to "lib«PROJECTNAME».dylib". I want the library to end with '.jnilib' since that is required by Mac OS X. So I patch this:
D2AAC09D05546B4700DB518D /* lib«PROJECTNAME».jnilib */ = {isa =
PBXFileReference; explicitFileType = "compiled.mach-o.dylib";
includeInIndex = 0; path = "lib«PROJECTNAME».jnilib"; sourceTree = BUILT_PRODUCTS_DIR; };
/* End PBXFileReference section */
Now, I want the header search paths to include the location of the Java headers, and the executable extension to be '.jnilib'. Searching the test project's '.pbxproj' file, I find them in the Debug and Release build sections. However, there are two pairs of these, one pair for the library target and one pair for the overall project. I need to change the ones for the overall project:
1DEB916508733D950010E9CD /* Debug */ = {
isa = XCBuildConfiguration;
baseConfigurationReference = 5073E0C609E734A800EC74B6 /* «PROJECTNAME»Proj.xcconfig */;
buildSettings = {
COPY_PHASE_STRIP = NO;
DEBUG_INFORMATION_FORMAT = dwarf;
EXECUTABLE_EXTENSION = jnilib;
GCC_ENABLE_FIX_AND_CONTINUE = YES;
GCC_OPTIMIZATION_LEVEL = 0;
HEADER_SEARCH_PATHS = "$(SDK)/System/Library/Frameworks/JavaVM.framework/Headers";
ZERO_LINK = YES;
};
name = Debug;
};
1DEB916608733D950010E9CD /* Release */ = {
isa = XCBuildConfiguration;
baseConfigurationReference = 5073E0C609E734A800EC74B6 /* «PROJECTNAME»Proj.xcconfig */;
buildSettings = {
ARCHS = (
ppc,
i386,
);
DEAD_CODE_STRIPPING = YES;
DEBUG_INFORMATION_FORMAT = "dwarf-with-dsym";
EXECUTABLE_EXTENSION = jnilib;
HEADER_SEARCH_PATHS = "$(SDK)/System/Library/Frameworks/JavaVM.framework/Headers";
PRESERVE_DEAD_CODE_INITS_AND_TERMS = YES;
SEPARATE_STRIP = YES;
};
name = Release;
};
I was encouraged when creating a new project didn't fail. Looking at the default setup, everything seems to be in order (no Carbon framework, all the boilerplate files are there, etc.). A few minutes to add in the JNI binding function and change the Java program to use the new JNI library and I have a successful test.
I'm sure there are many other customizations I could make if I only knew about them. I also wish there were a better tool than a text editor for editing these files (hopefully there is and someone will point it out to me).
Sunday, January 21, 2007
Learning Cocoa
If you have any interest in the Cocoa frameworks for Mac OS X, you might be interested a blog entry about learning how to program Cocoa. It's on my other blog, Walking the Fringe, because it's more exploratory than the material I like to put on this blog.
Friday, January 19, 2007
Configuring logging in your Spring configuration file
I detest multiple configuration files. Generally, I can't avoid having them, but whenever I can find a way to reduce the number of configuration files, the better.
So, when I need to tailor the logging levels in my application, I have a choice: edit the default logging file (possibly effecting other applications if that copy of the JDK is shared as is typical), or create a separate logging configuration file and point logging to it (in the case of the JDK's logging, this means setting the java.util.logging.config.file property).
When using Spring, I'd really like to put my custom logging levels in my Spring configuration file, so I don't have yet another file that has to travel with my application. There doesn't appear to be any way built into Spring to do this, but by adding a tiny Java class to the application (one that is reusable for each application), we gain the ability to do this.
The idea is to create a bean at the top of your Spring configuration file that will set your custom logging levels. For example:
The LoggingConfigurer class is trivial:
Now, when Spring is initialized, very early on in the process, it encounters the entry for our loggingConfigurer bean. Since the bean has lazy initialization turned off, it is immediately created and configured. That sets our logging levels to what we want.
Admittedly, this isn't perfect. For example, these few lines of logging show up when launching a Spring and Hibernate application (prior to our bean turning the logging level to WARNING):
But this is a great improvement over the huge amounts of output from Spring and (especially) Hibernate that show up otherwise.
I'm sure a similar approach can be used with log4j. If anyone adapts this to log4j I'd love to know how that works.
So, when I need to tailor the logging levels in my application, I have a choice: edit the default logging file (possibly effecting other applications if that copy of the JDK is shared as is typical), or create a separate logging configuration file and point logging to it (in the case of the JDK's logging, this means setting the java.util.logging.config.file property).
When using Spring, I'd really like to put my custom logging levels in my Spring configuration file, so I don't have yet another file that has to travel with my application. There doesn't appear to be any way built into Spring to do this, but by adding a tiny Java class to the application (one that is reusable for each application), we gain the ability to do this.
The idea is to create a bean at the top of your Spring configuration file that will set your custom logging levels. For example:
<bean id="loggingConfigurer"
class="com.acme.logging.LoggingConfigurer"
lazy-init="false">
<constructor-arg>
<props>
<prop key="org.springframework">WARNING</prop>
<prop key="org.hibernate">WARNING</prop>
</props>
</constructor-arg>
</bean>
The LoggingConfigurer class is trivial:
package com.acme.logging;
import java.util.Iterator;
import java.util.Properties;
import java.util.logging.Level;
import java.util.logging.Logger;
/**
* Configures logging by being constructed.
* Especially useful when created as a bean from a Spring configuration file.
*/
public class LoggingConfigurer {
public LoggingConfigurer(Properties props) {
Iterator i = props.keySet().iterator();
while (i.hasNext()) {
String loggerName = (String) i.next();
String levelName = props.getProperty(loggerName);
try {
Level level = Level.parse(levelName);
Logger l = Logger.getLogger(loggerName);
l.setLevel(level);
}
catch ( IllegalArgumentException e ) {
System.err.println( "WARNING: Unable to parse '"
+ levelName + "' as a java.util.Level for logger "
+ loggerName + "; ignoring..." );
}
}
}
}
Now, when Spring is initialized, very early on in the process, it encounters the entry for our loggingConfigurer bean. Since the bean has lazy initialization turned off, it is immediately created and configured. That sets our logging levels to what we want.
Admittedly, this isn't perfect. For example, these few lines of logging show up when launching a Spring and Hibernate application (prior to our bean turning the logging level to WARNING):
Jan 19, 2007 3:44:41 PM org.springframework.core.CollectionFactory
INFO: JDK 1.4+ collections available
Jan 19, 2007 3:44:41 PM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
INFO: Loading XML bean definitions from class path resource [baseContext.xml]
Jan 19, 2007 3:44:41 PM org.springframework.beans.factory.xml.XmlBeanDefinitionReader loadBeanDefinitions
INFO: Loading XML bean definitions from class path resource [unitTestingContext.xml]
Jan 19, 2007 3:44:41 PM org.springframework.context.support.AbstractRefreshableApplicationContext refreshBeanFactory
INFO: Bean factory for application context [org.springframework.context.support.ClassPathXmlApplicationContext;hashCode=2490106]: org.springframework.beans.factory.support.DefaultListableBeanFactory defining beans [loggingConfigurer,hibernateStatsService,mbeanServer,exporter,persistence,setPersistenceManager,customEditorConfigurer,mySessionFactory]; root of BeanFactory hierarchy
Jan 19, 2007 3:44:41 PM org.springframework.context.support.AbstractApplicationContext refresh
INFO: 8 beans defined in application context [org.springframework.context.support.ClassPathXmlApplicationContext;hashCode=2490106]
Jan 19, 2007 3:44:41 PM org.springframework.context.support.AbstractApplicationContext initMessageSource
INFO: Unable to locate MessageSource with name 'messageSource': using default [org.springframework.context.support.DelegatingMessageSource@a9a32c]
Jan 19, 2007 3:44:41 PM org.springframework.context.support.AbstractApplicationContext initApplicationEventMulticaster
INFO: Unable to locate ApplicationEventMulticaster with name 'applicationEventMulticaster': using default [org.springframework.context.event.SimpleApplicationEventMulticaster@2153fe]
Jan 19, 2007 3:44:41 PM org.springframework.beans.factory.support.DefaultListableBeanFactory preInstantiateSingletons
INFO: Pre-instantiating singletons in factory [org.springframework.beans.factory.support.DefaultListableBeanFactory defining beans [loggingConfigurer,hibernateStatsService,mbeanServer,exporter,persistence,setPersistenceManager,customEditorConfigurer,mySessionFactory]; root of BeanFactory hierarchy]
But this is a great improvement over the huge amounts of output from Spring and (especially) Hibernate that show up otherwise.
I'm sure a similar approach can be used with log4j. If anyone adapts this to log4j I'd love to know how that works.
Wednesday, January 17, 2007
Simplified Database Management in Spring-based Hibernate Unit Tests
I've been working with Hibernate recently, and needed a way to implement good unit tests. The goal of these unit tests is to make sure the Java code works in conjunction with the Hibernate mapping files. I found an excellent article on using HSQLDB to do unit testing of Hibernate classes on The Server Side.
Unfortunately, one of the drawbacks of the approach described is that it requires you to write some custom JDBC code to clear out your tables after each unit test. From the article:
Another possible option for handling this scenario if you are using Hibernate 3 is to use it's bulk update feature. I haven't used this feature yet, but apparently one wrinkle is that bulk deletes don't seem to cause cascade deletes. This requires that you remember to update your code each time you add a new table to those used by your application, or end up with problems in your unit tests due to data left over from the last test method.
But in my opinion there's a better way: leverage the SchemaExport utility of Hibernate to automaticallly wipe out and recreate all your tables for you. The basic idea is that the setUp method of your unit test calls the SchemaExport utility to wipe out the existing tables and recreate them. This leaves you with the proper tables and a clean slate upon which to create exactly the objects needed to run your test. This simplifies your unit testing and avoids having to maintain both the mapping files and the bulk delete code in tandem.
To accomplish this, you need to make sure your Hibernate mapping files specify enough information for Hibernate's SchemaExport utility to generate and run database-specific DDL to recreate your tables, indexes, foreign keys, etc. For example, you might have a mapping file for a SimplePerson class that looks like this:
You need to make sure you have information about the SQL types of your mapped columns so Hibernate knows how to generate the tables, like this:
The sql-type attributes are what tell Hibernate how to generate DDL for your table. Once you have this, you can invoke the SchemaExport utility on your in-memory HSQLDB database and it will wipe out the old tables and their contents and recreate them empty.
Now our only catch is invoking SchemaExport when using the Spring framework. If you're using Spring outside of any other container, you might use a LocalSessionFactoryBean to do your Hibernate mapping work, like this:
This is great, except for one thing: you need access to the Hibernate Configuration object in order to invoke SchemaExport and this is not easily available (from what I can find). There is nice workaround for this problem, though. If you use the ampersand ('&') character in front of the name of a bean, you can get at the actual Spring object instead of the bean it creates. For example, the LocalSessionFactoryBean has a public getConfiguration method will get us the Hibernate Configuration object we want. So we can implement a setUp method that contains code like this:
Now, every test method in your unit test will have a clean database with all the right tables, indexes, etc.
One side benefit of this is that there's a good chance you will make the tests run faster than when connecting to an external database. But, most importantly, by avoiding dependencies on an external database you improve the reliability of your Hibernate mapping unit tests.
Unfortunately, one of the drawbacks of the approach described is that it requires you to write some custom JDBC code to clear out your tables after each unit test. From the article:
statement.executeUpdate("delete from Batting");
statement.executeUpdate("delete from Fielding");
statement.executeUpdate("delete from Pitching");
statement.executeUpdate("delete from Player");
connection.commit();
Another possible option for handling this scenario if you are using Hibernate 3 is to use it's bulk update feature. I haven't used this feature yet, but apparently one wrinkle is that bulk deletes don't seem to cause cascade deletes. This requires that you remember to update your code each time you add a new table to those used by your application, or end up with problems in your unit tests due to data left over from the last test method.
But in my opinion there's a better way: leverage the SchemaExport utility of Hibernate to automaticallly wipe out and recreate all your tables for you. The basic idea is that the setUp method of your unit test calls the SchemaExport utility to wipe out the existing tables and recreate them. This leaves you with the proper tables and a clean slate upon which to create exactly the objects needed to run your test. This simplifies your unit testing and avoids having to maintain both the mapping files and the bulk delete code in tandem.
To accomplish this, you need to make sure your Hibernate mapping files specify enough information for Hibernate's SchemaExport utility to generate and run database-specific DDL to recreate your tables, indexes, foreign keys, etc. For example, you might have a mapping file for a SimplePerson class that looks like this:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD/EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="com.acme.project">
<class name="SimplePerson" table="PERSONS">
<id name="id" type="int">
<column name="CODE" not-null="true"/>
<generator class="native"/>
</id>
<property name="firstName" column="FIRST_NAME" not-null="true"/>
<property name="lastName" column="LAST_NAME" not-null="true"/>
<property name="contactEmail" column="CONTACT_EMAIL_ADDRESS"/>
<property name="disabled" type="boolean">
<column name="DISABLE" default="0" not-null="true"/>
</property>
</class>
</hibernate-mapping>
You need to make sure you have information about the SQL types of your mapped columns so Hibernate knows how to generate the tables, like this:
<?xml version="1.0"?>
<!DOCTYPE hibernate-mapping PUBLIC "-//Hibernate/Hibernate Mapping DTD/EN"
"http://hibernate.sourceforge.net/hibernate-mapping-3.0.dtd">
<hibernate-mapping package="com.acme.project">
<class name="SimplePerson" table="PERSONS">
<id name="id" type="int">
<column name="CODE" sql-type="integer" not-null="true"/>
<generator class="native"/>
</id>
<property name="firstName" column="FIRST_NAME" not-null="true"/>
<property name="lastName" column="LAST_NAME" not-null="true"/>
<property name="contactEmail" column="CONTACT_EMAIL_ADDRESS"/>
<property name="disabled" type="boolean">
<column name="DISABLE" sql-type="int" default="0" not-null="true"/>
</property>
</class>
</hibernate-mapping>
The sql-type attributes are what tell Hibernate how to generate DDL for your table. Once you have this, you can invoke the SchemaExport utility on your in-memory HSQLDB database and it will wipe out the old tables and their contents and recreate them empty.
Now our only catch is invoking SchemaExport when using the Spring framework. If you're using Spring outside of any other container, you might use a LocalSessionFactoryBean to do your Hibernate mapping work, like this:
<bean id="mySessionFactory" class="org.springframework.orm.hibernate3.LocalSessionFactoryBean">
<property name="mappingResources">
<list>
<value>com/acme/project/SimplePerson.hbm.xml</value>
<!-- ... -->
</list>
</property>
<property name="configLocation" value="hibernateConfig.xml"/>
</bean>
This is great, except for one thing: you need access to the Hibernate Configuration object in order to invoke SchemaExport and this is not easily available (from what I can find). There is nice workaround for this problem, though. If you use the ampersand ('&') character in front of the name of a bean, you can get at the actual Spring object instead of the bean it creates. For example, the LocalSessionFactoryBean has a public getConfiguration method will get us the Hibernate Configuration object we want. So we can implement a setUp method that contains code like this:
LocalSessionFactoryBean l = (LocalSessionFactoryBean) factory.getBean("&mySessionFactory");
Configuration cfg = l.getConfiguration();
SchemaExport schemaExport = new SchemaExport(cfg);
schemaExport.create(false, true);
Now, every test method in your unit test will have a clean database with all the right tables, indexes, etc.
One side benefit of this is that there's a good chance you will make the tests run faster than when connecting to an external database. But, most importantly, by avoiding dependencies on an external database you improve the reliability of your Hibernate mapping unit tests.
Wednesday, January 10, 2007
Hibernate: Simple Classes Aren't So Simple
I was fighting with Hibernate the other day, trying to figure out why it was giving me a query error. After much too long, I decided to implement unit tests for my measly two classes, which I thought were too simple to really need unit tests.
Almost immediately, I found bugs in one of the two persistent classes I was working with that were confusing Hibernate and leading it to generate the error message that was confusing me.
I checked the Hibernate best practices page and my lesson isn't listed. It may sound obvious, but here it is:
While your classes may be simple, Hibernate is not. Always implement a unit test to verify that the simple parts of your persistent objects are mapped correctly by Hibernate before moving on to more complex issues like inheritance, relationships, containment, etc.
Almost immediately, I found bugs in one of the two persistent classes I was working with that were confusing Hibernate and leading it to generate the error message that was confusing me.
I checked the Hibernate best practices page and my lesson isn't listed. It may sound obvious, but here it is:
While your classes may be simple, Hibernate is not. Always implement a unit test to verify that the simple parts of your persistent objects are mapped correctly by Hibernate before moving on to more complex issues like inheritance, relationships, containment, etc.
Subscribe to:
Posts (Atom)